
Le monde du martech s’affuble d’un nouvel acronyme, la « CDP », Customer Data Platform, intronisée en France ce 1er octobre 2019 par une conférence chez OnePoint qui lui était dédiée, organisée par le CDP institute, association non lucrative soutenue par tous les éditeurs de CDP.
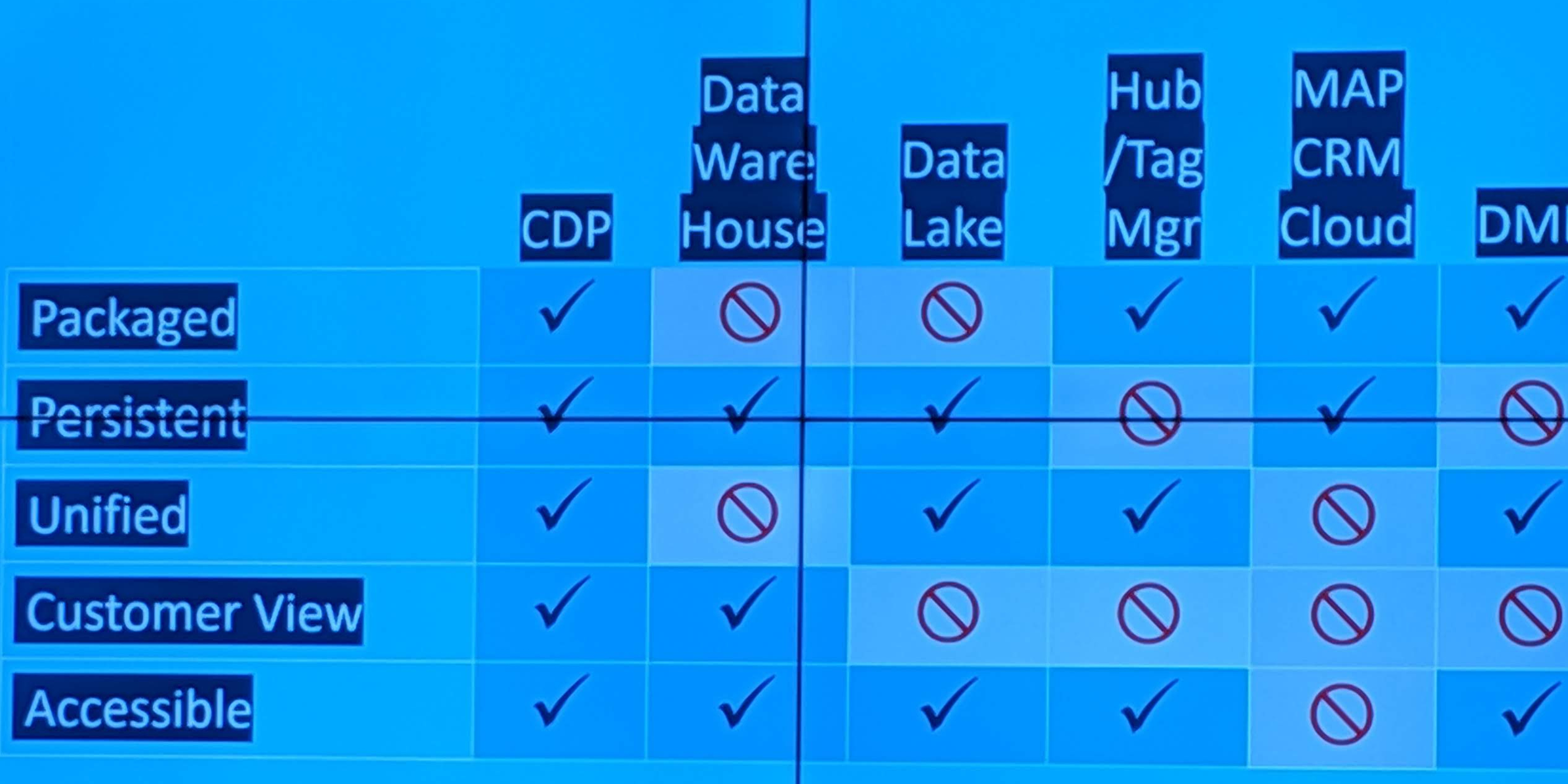
Cet institut a défini la CDP par 5 grandes caractéristiques:
- Capacité à ingérer tous types de données clients identifiés sans avoir à structurer un data model ou une infrastructure (vs datawarehouse ou datalake)
- Stockage de la majeure partie des données client
- Persistance du stockage (vs les DMP qui n’allait qu’on maximum jusqu’à 13 mois légalement, et 3 mois maximum en pratique)
- Unification des profils (à partir d’une clé de réconciliation bien sûr, de ce point de vue, c’est une fonction identique à une DMP)
- Disponibilité de l’information à n’importe quel autre système externe (vs les systèmes CRM opérationnels qui ne peuvent en même temps gérer des transactions et la mise à disposition)

Ces caractéristiques sont suffisamment discriminantes pour permettre de facto de définir ce qu’est une CDP et ce qui n’est en pas, afin d’aider les marketers à s’y retrouver et éviter de les confondre avec des datalakes, des datawarehouses, des DMP, des gestionnaires de campagnes ou des solutions CRM.
En effet, ces caractéristiques apportent de nouvelles possibilités qu’aucun des autres outils martech n’apportaient jusqu’à présent :
- Un accès simplifié à toute la donnée client (le fameux 360 !)
- Une profondeur de donnée qui va bien au-delà des bases RCU historiques qui ne vont pas beaucoup plus loin que les golden records. Plus besoin de piocher dans plusieurs bases à la fois pour calculer des KPI ou avoir des extractions.
- Une information temps réelle permettant d’activer immédiatement dès qu’un événement est détecté, et offrant une réelle capacité de conversation avec le consommateur et sa personnalisation.
- Une interface permettant de facilement segmenter à la volée les clients.

Malgré tout, les CDP du marché ne sont pas toutes similaires. Elles ont toutes des valences différentes. Certaines sont plutôt orientées data , analytics, ou gestion de campagne. En effet, beaucoup des solutions du marché n’ont pas été conçues d’entrée comme des CDP. Par Exemple Tealium était au départ un tag manager et a ajouté une fonction de server side permettant d’échanger directement de la données vers les systèmes d’information sans utiliser le navigateur et c’est ce qui lui permet aujourd’hui de figurer parmi les CDP.
Cette conférence a permis d’entendre le témoignage de Castorama et Brico Dépôt du groupe Kingfisher qui a mis en place la CDP Tealium justement.
Concrètement, parmi les clients intéressés par les salles de bain , la CDP a permis d’identifier un segment de 1% d’entre eux pour lesquels les campagnes de search ont eu un ROI 6 fois plus important que sur les autres segments… et le panier moyen 10 fois supérieur que les autres. Ces résultats ont pu être répliqués pour les clients intéressés par la décoration d’intérieur, démontrant la scalabilité de ce type de démarche.
Mais ce qui est encore plus intéressant dans ce témoignage, c’est le constat que la mise en œuvre de cette CDP n’a pas été vécue comme un projet technique, mais comme un vrai projet métier. En effet, la dimension technique passe clairement en second plan car la complexité de mise en œuvre est relativement faible. Cela a été souligné par un autre exemple cité par l’éditeur Treasure data au sujet de l’implémentation de sa CDP pour une grande marque de bière internationale, l’aspect formation et montée en compétence ont été négligés et a pénalisé fortement les performances.
Pour Omnicom, qui témoignait aussi, la CDP se justifie que pour les marques :
- Pour lesquelles l’achat est impliquant pour le consommateur (pour l’aider à faire son choix)
- Et/ou il y a un repeat important
- Qui ont des données clients, cela va mieux en le disant (cf certaines marques CPG qui en sont démunies)
Et la condition du succès est bien sûr d’avoir du contenu à proposer à ses client et qui soient en phase avec leur situation dans la funnel…ce qui est un gros challenge car les modes opératoires et les budgets des annonceurs ne sont pas adaptés à cette nouvelle exigence : l’absence de contenu pertinent gâche l’investissement dans les outils. C’est assez facile à dire et beaucoup plus dur à faire. C’est un nouveau type de travail créatif auquel peu d’agence sont encore habitués. Et il cela conduit aussi à une question de coûts de production de ces contenus car comment en produire plus sans exploser les budgets…mais c’est un autre sujet.
La CDP a clairement un potentiel important et des effets insoupçonnés qui vont au-delà de la simple performance. Elle impacts aussi les organisations car elle permet plus facilement de partager les informations. Omnicom citait l’exemple d’Ubisoft qui a modifié son organisation marketing qui était structuré par jeu car la donnée d’un joueur sur les différents jeux n’étaient pas disponibles avant la CDP . Ubisoft a depuis créé un département marketing transversal. Chez Kingfisher, l’efficacité observée sur les actions marketing en direction des clients conduit à modifier la répartition des budgets crm vs prospection au bénéfice du crm.
Concertant la mise en place et l’exploitation, la CDP n’est pas très lourde pour les organisations mono marques, et devient plus lourde quand il y a plusieurs marques à gérer. W3 régie qui gère sa CDP avec de nombreuses enseignes du groupe Casino dédie 8 personnes à temps plein (2 business owners, 2 data scientists, 2 data analystes et 2 ops). La maturité de la marque joue aussi beaucoup. La présence d’un datalake où toutes les informations des applications métier client sont déjà stockées accélère beaucoup le déploiement puisque tous les travail de structuration de la donnée a déjà être fait au moment où il faut y connecter la CDP.
Venons en maintenant à toutes les questions qui se posent et qui n’ont pas été abordées pendant cette conférence.
Faut-il absolument une DMP en plus d’une CDP pour activer du média ?
A priori non car beaucoup de CDP disposent de connecteurs au DSP du marché. En outre, le bénéfice de partager ces données avec des third party, qui est le point de fort des DMP, devient de moins en moins avéré du fait de la régulation plus stricte de la GDPR. Au final, une CDP connectée au DSP suffit largement dans beaucoup de cas.
Peut-on recycler une DMP en CDP ?
Cest la bonne question car en fait une DMP peut assurer une bonne partie des fonctions de la CDP si on sait correctement l’utiliser. Il est effectivement dommage que beaucoup de DMP du marché n’ait été utilisées que pour du média car cela a conduit à beaucoup de déceptions, et a encouragé beaucoup de marketers à jeter le bébé avec l’eau du bain. Or les DMP ont des fonctionnalités très similaires au CDP dès qu’elles sont correctement alimentées en amont par un flux CRM structuré et qui est anonymisé à la volée. Beaucoup de use case de CDP (ex : arrêter d’envoyer de la publicité à ces clients) peuvent donc être réalisés avec une DMP pour peu qu’on fasse cet effort, effort qu’il faudra faire quoi qu’il arrive avec une CDP. Si la DMP est donc encore active, il y a une belle opportunité à tester de uses case de CDP s’il fallait en passer par là pour justifier la CDP.
CDP et DMP doivent elle coexister ?
Tout va dépendre de la situation de la marque et de son business modèle. Si elle nécessite beaucoup de dépenses média avec beaucoup de repeat, qu’elle dispose de peu d’information client, et qu’il y a un beaucoup d’optimisations possibles sur le média, la DMP est probablement à conserver (cas de CPG). A l’inverse, en cas de faible répeat, de cycle courts et de beaucoup de données clients (cas des banques pour les crédits immobiliers), la CDP doit être favorisée par rapport à la DMP.
Combien coûte une CDP vs un DMP ?
Les CDP ont des modèles de facturation qui sont souvent liés à de l’usage comme les DMP. Et comme pour le DMP, il faudra particulièrement examiner les coûts en particulier pour les solutions américaines qui ne se rendent pas bien compte qu’il faut adapter les prix en fonction des volumes de marché. Les DMP ont beaucoup souffert de coût disproportionnés. Ce qui est absorbable dans un marché US, ne l’est plus du tout sur un marché de la taille de la France, d’autant que les efforts d’intégration sont les mêmes quel que soit la taille du pays. La même chose est à craindre pour le CDP.
La CDP permet-elle de s’abstenir d’avoir un datalake ou un datawarehouse ?
A priori, non. Le datalake reste toujours le meilleur outil pour les analyses poussées des data scientists, le calcul de score et pour servir d’environnement intermédiaire de stockage et de traitement des données avant injection ailleurs. La datawarehouse demeure nécessaires pour assurer les fonctions de reporting et d’analytics. Quoique les CDP vont probablement se développer vers ces fonctions car elles sont temps réel. Mais leur logique de facturation ne vont pas faciliter les choses car on risque de payer à chaque consultation de reporting, ce qui n’est pas acceptable, et cela placera les datawarehouse en meilleure position pour assurer ces fonctions.
La CDP peut-elle remplacer le RCU ?
La CDP dispose de l’avantage d’être nativement conçue pour facilement distribuer son information via des Api. Et puisqu’elle possède et unifie toutes les données client, c’est un bon candidat pour remplacer le RCU à terme. Mais attention, là encore au système de facturation. Le RCU est souvent une solution facturée au volume de données stockées et non au nombre d’appels…ce qui n’est pas toujours le cas des CDP. Donc une analyse des coûts s’impose, même si techniquement, la CDP pourrait bien facilement remplacer un RCU.



